Many database applications are based on relationship models which are one-directional but there are other patterns that we will need from time to time. In this article we’ll discuss several common design patterns and then look at a more unusual pattern which can be used to handle situations which are difficult to structure or have an indefinite structure.
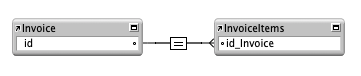
The data pattern most commonly used in my programming is a one-to-many relationship, often called the “Parent-Child” relationship and it is comprised of two tables. A typical use for the one-to-many relationship is to create an invoice. The “parent” table is the invoice and the other table records the “children” linked to the invoice. Each record in the invoice items table stores the ID of the invoice record. This is also described as 1:n. There is one record ( the invoice) that is related to many (n) other records ( the line items ).


Another common case is the many to many relationship. This is an extension of the one-to-many relationship. It is actually two one-to-many relationships joined together and the table in the middle is called the “join” table. In the diagram below there are many orders and many products, they are linked using the OrderItems table. A product will appear on many orders and an order may include many products.



The many to many relationship is very common but there is a specialised variation which is not used as frequently, called the component/manufacturer design pattern. This could be used in a workshop that builds vehicles or a restaurant. This pattern uses a third table, called a join table to describe the relationship between products and components. The distinguishing feature of this pattern is that it is a self-join pattern. This manufacturer design pattern is called a self-join because the join table is used to link the components/ingredients table to itself.
This pattern is sometimes called a hamburger join because many examples use a hamburger recipe to illustrate the concept. A recipe database may record ingredients that are used to make different foods. The same ingredient, e.g., flour, is used in many different recipes, e.g., bread, buns, cakes, and so on. The food produced by one recipe may then be used in other recipes. For example, flour and water is used to make buns, meat and eggs make patties, patties and buns make hamburgers, hamburgers are served in combo meals, and so on. That is the component/manufacturer pattern.



All of the relationships we’ve looked at are patterns that are designed to aggregate many records with one or more records but there is a need for patterns that only allow a relationship to one other record. There are two basic situations. The most frequent is when a record in one table may only link to one other record in another table. This is a many-to-one ( n:1 ) relationship. A one-to-one relationship occurs when there are validation rules to prevent any of the records in either table being linked to more than one record in the other table.



Design Patterns for Peer Relationships
The one-to-many and many-to-many examples we’ve described are relationships that have formal or fixed roles. Invoices are always invoices, invoice items are always invoices items. Similarly for orders, we order products and we use the intermediary table to link the two in a rigid structure. The manufacturing pattern is slightly different because it allows a product to be a component/ingredient in other products. This is much more complex than both the invoice and the order and requires special handling. However, the relationship between components and products is still tightly structured.
In addition, all of the other patterns we’ve discussed tend to have a principal entity which are complicated by dependencies. But reciprocal relationship are more egalitarian. This type of relationship is useful when we want to share the “join” information equally between both entities.
Reciprocal relationships occur in many environments. People-centered applications often require a pattern which can work in both directions from person to person. In these cases we want a “peer to-peer” pattern, not a parent-child pattern.
The best example of complex peer relationships comes when we try to describe the way our families and friends. Social, cultural and genealogical relationships get messy. People have children to many partners. Your siblings may have different parents to your own. In that case your generation of the family has more than two parents. A friend may marry one of your siblings, they are suddenly an “in-law.” Your friendship families are now linked by marriage. The real family tree is not a simple branching structure – it’s a dense, entangled forest.
We’ve created a lot of different solutions for this problem over the years. All of them have been more or less successful but it was always apparent that we hadn’t solved the problem in a way that let us sleep quietly at night. The signals that the design pattern wasn’t right was that it was fragile or brittle ( code for would break easily ) and that it needed a lot of band-aids ( either scripts or layout work ).
What we needed was something that worked in all environments: FileMaker Pro, FileMaker Go, client/server, WebDirect or via the web APIs. Not only did it have to be simple and robust. It had to be able to be defined in the relationship graph and work without external support from scripts and/or layout level trickery.
The design we arrived at is a many-to-many pattern that is based on equality criteria. satisfies criteria for normalised data. It allows for the automatic generation and destruction of intermediate data. It is defined entirely in the relationship graph and it is robust.
The Reciprocal Join design pattern that we use ( get the download below ) provides a method for data to be shared between entities with equal bias toward them both. It is a useful way to record shared attributes between two entities which are difficult to structure or have an indefinite structure and need to be available to both.



The crux of the design pattern is that we relate the two join tables to each other. By using the auto-create features in the relationship graph we are able to manage the generation of the records in the intermediate tables. This also allows us to normalise the data and avoid duplicating the data in both join tables.
The reciprocal pattern does not have to be used a self-join context. It is shown in a self-join context in the diagram above and in the attached file but it can be used to link two different entities.
Feel free to download the attached FileMaker database and explore the reciprocal relationship. The relationship graph of the file also includes examples of all the other relationships discussed in this article.
Photo by kabita Darlami on Unsplash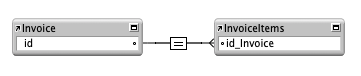{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Interesting article. I do not see a link to download the database.
Ah, I’d limited access to content and it seems as though I had been too strict. You should see them now.