This is the second part in a series discussing design patterns for Claris FileMaker databases. The first part discusses the use of data layers, check it out first if you haven’t read it already.
What are Key tables, also known as “no data” tables?
In this article we introduce Key tables. Key tables are an efficient way to manage user access to the data in the layers and the core. A key table gets its name because a record in a key table contains only enough information to establish a one-to-one relationship with the record it is related to, that is the key or ID of the related record. For this same reason, key tables are also called “no data tables.”
In the diagram below we have extended the design pattern we saw in the data layers article to include key tables. You can see that the key tables have only one field, the foreign key of the related table.


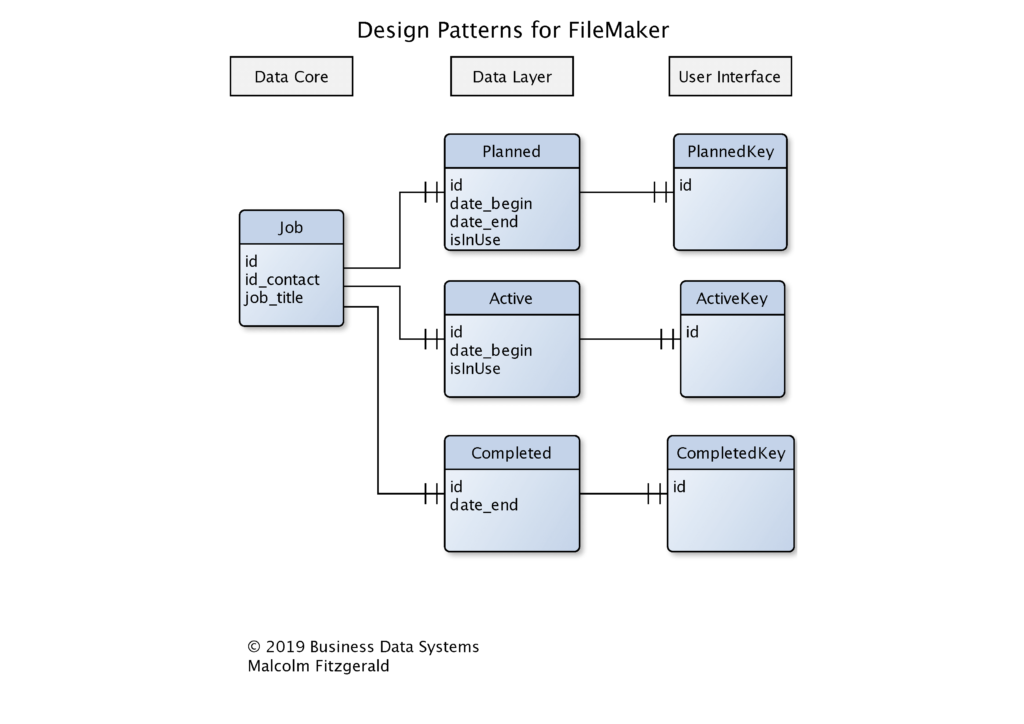
Why use Key tables or No Data tables?
There are many reasons for using key tables. The first reason that is most often given for their use is to reduce the size of data transfers. However, this is only possible because they allow us to express complex behaviours in our applications. In a word, they give us control. With control comes power, and so it is with key tables.
Minimising Bandwidth
The first and most broadly applicable reason for using key tables, regardless of the programming platform you use, is to reduce the size of data transfers. Whatever you are coding, this is a good reason to use key tables. For FileMaker developers this will have particular interest when you are delivering content to mobile users via FileMaker Go or WebDirect; when you have users connecting via the WAN; or you are using any of the data transfer technologies, such as ODBC, JDBC, the PHP/XML API or the Data API.
A core feature of the Claris FileMaker product is that treats records as a data unit. When you request a record, you receive the data for every field in that record. On the local area network, where you have fat pipes, this is a good thing. FileMaker is optimised to take advantage of this, so it can work in your favour.
When we step outside the office, into the world, where we have to rely on low bandwidth networks, a database that has data-rich default behaviour may start to work against us. In the diagram below we’ve taken a table from a common CRM and put it beside a low-data table and a no-data key table. You can see at a glance that there could be a lot of data in every contact record. If our plan is to present a list of names, expecting the user to choose one, then we don’t really want to send the addresses, birthday, etc, for every person in the list. That is a big waste of bandwidth and a waste of time for a list of names.
At the other end of the diagram you can see the no-data table only contains an ID. That isn’t enough information when we want to present a list of names – or is it?



Control
The second reason for using key tables is that they allow us to express complex behaviours in our applications. A no-data key table provides us with great opportunities to utilise core methods that are engineered into the FileMaker platform. Our first example of this is that it gives us control over the data set delivered to a user. Using a layout based on a key table we can control which fields are displayed to the user. We can the display of fields with a layout based on the original table too but using a key table allows us to exploit another feature built-in to the core of the FileMaker platform.
When you request a record, or a record set, from FileMaker, it is always done from the context of a layout. As we know, a record will return the data from every field in the table. If a layout contains fields from any related records, those related fields will be included in the record data too. Importantly for us, only the related fields which are displayed on the layout are included, not the entire set of fields from the related table.
We now know that a record delivers every field from the local table, regardless of what is on the layout, and in addition, any fields from related tables, and only those fields. We can use this to our advantage. For our example, let’s say we want our sales team to know the spending patterns and social value category of our customers. We’re pushing the contacts table out to mobile phones via Go or WebDirect. We want to provide a list of contacts that is scrollable and searchable. We’ll supply Five fields. The first name, last name, total spend, frequency of spend and social value category.
If we design a list layout for the iPhone that displays a dozen records at a glance, and which is based on the table occurrence “AWideTableOfContacts” we now know that we will transmit every field for every contact record plus the spending and social value fields from the ModelLowData table. That is approximately fifty fields. And we know1 that FileMaker will pull down a buffer of records in anticipation of scrolling. Let’s say that is 36 records, and assume that each record contains 10Kbytes of data or 1MB for every 100 records.
1MB for every 100 records is not a huge amount but it is unnecessary. If we base the layout context on the LowData table we have only six fields that must be transferred and the first name and last name fields. That is only eight fields in total rather than fifty fields in total. If we base the layout on a no data table we must transmit one field – the ID – plus the five fields that we want to display to our sales team. Now we’re transmitting – let’s say about 20bytes for each field – and there are six fields. That’s only 12Kb per 100 records. The data load has been reduced to a fraction of what it was initially – the total size is only a little more than sending a single record from a layout based on the contacts table.
And, when one of our sales team selects a record to obtain more information, we can continue to use the no-data table as the layout context. That ensures that we transmit the information that is required for the task at hand and nothing more. Not only is this a great improvement for performance and bandwidth, it is a security improvement too, as we have have reduced the opportunity for data leaks too.
Exploiting the Standard Behaviours of the Platform
In our previous article on data layers we saw that creating tables that were specific to a subset of data had positive benefits for us. The FileMaker application supported the data layers concept, allowing us to use the entire application in a very open and simple way. No-data key tables allow us to extend those gains. We’ll quickly look at a very important areas for database managers: preserving data integrity.
Data Integrity
Users love to delete data! It’s shouldn’t be the highlight of your day but sometimes, hitting that delete button brings immense satisfaction. Database admins, on the other hand, have a calling to protect data. In a relational database, deleting data can cause massive headaches. If a product or a contact is removed from a relational database the gap can ripple through the system causing a lot of damage. Key tables can provide a simple solution to this dilemma.
Remember that our key tables are “no data” tables. They don’t have any unique data, they only store the ID needed to establish a relationship with the tables that actually store data. If you looked at the ERD image carefully you may have noticed that the key tables were grouped under the label, “User Interface.” Using the key table as the context for layouts provided to users is a way of protecting the data, while allowing the user the satisfaction of using the delete key. This is not an illusion of deleting (using scripted search/hide techniques or user permission sets). It is a real delete, so all of the behaviours, such as found set, active/passive button states, etc, that are built-in to the user interface are automatically invoked.
In this scenario, the table contexts for all the user interface layouts are created from key tables. If a user deletes a record in a key table nothing has been lost. Certainly, the record in the key table has been lost but none of the data from any of the actual data tables has been removed. The user has the satisfaction and assurance that there is one less record in the table. The data related to that record is no longer visible via the key table. However, no data has been destroyed. All other records which rely on the existence of the data can still find it, so data integrity is preserved.
Bring Data back from the Dead
There is another, related benefit of using no-data key tables in the user interface. After a user deletes a record in the key table, all the actual data remains in place. This means it is extremely easy for database admins or managers to recover/replace/rebuild the record in the key table. All that is required is to create a new record in the key table with the ID of the “deleted” record. As soon as that has been done, the user interface will display the related data sets. Rebuilding the key record can be done in a variety of ways from the simple search (omit records in the data table that have a matching key in the key table) to a more complex system ( such as an action log ). All that is needed is to create a new record with the correct ID.
The preservation of data integrity goes much further than keeping links between data intact. Internal metadata, such as the modification time and date, the internal serial number and the modification count are out of the reach. This information cannot be touched by the user or the system developer. Systems that move the data into an archive and back cannot retain data integrity at that level, it is beyond their control.
From a forensic point of view there is a vast difference between a record that has not been touched and a record which has been rebuilt/restored from an archived data set. Systems which use data flags, i.e., setting a field such as “isDeleted” to true or false fall foul of this too because they are modifying the records. The use of key tables ensures that data has not been tampered with.
Summary
Key tables allow us to express complex behaviours in our applications. They take advantage of core behaviours in the FileMaker platform. These give you, as a developer, an advantage, because you are using stable, built-in methods. Key tables can be used to improve performance in mobile solutions. They can be used to consolidate data integrity. They can be used in a variety of ways that we haven’t explored here. There is very little extra work required to key tables to your system and many benefits flow from them.
Attachments
{kind=link}
{kind=link}
{kind=link}
- FileMaker Server will pre-cache data. We haven’t discussed it in this article. [↩]
hi Malcolm, I’m interested in the comment about reducing bandwidth because the key table has fewer fields thus less data to transfer. It has always been my understanding that while this is true, the actual rule is “if you touch it, you download it”. So while a key-table itself does have less content to transfer, as soon as you use that key table to relate to the actual data, and show any data from the data core, then you are still sending over the wire the full record from the table itself anyway., meaning you aren’t really getting much of an improvement in performance – if anything less because there is the data core record to download, plus a key record, and an extra relationship to evaluate ?
Hi Daniel,
I must update this article. Following your comment and questions from others I’ve asked for clarification from Claris. You are correct. For FileMaker clients, you touch it you download it. My misunderstanding arose because I was developing for web interaction using the APIs when I first discussed this with the Claris Engineers. At that time, I was given the information without the proviso that it only applied in the web context.