Design Patterns in FileMaker is a set of articles which discuss common data modelling problems in the context of FileMaker.
Data layers simplify common data modelling problems. Data layers share the same core data and typically include several extra attributes which are unique to that layer.
What is the Problem?
The need for data layers arises when we have several discrete uses for a core set of data. We don’t want to replicate the core data for each use case because it makes extra work in maintaining tables and fields, business logic, scripts and layouts.
Many FileMaker databases start small and grow, rather than being planned from the top down. We often start with a fairly broad data set, such as “contacts”. Over time, the amount of data grows and the function requirements of the database increase too. At some point we want to be able to differentiate between the type of contacts. A common need is to separate our Customers from our Suppliers.
It is possible to do this in many ways. The most common being to control the found sets, either manually or by scripting. That works perfectly well and is the most common method because it is the easiest and most direct means of grouping data within a table. When you do this the user interface will provide you with feedback about those actions. In the screen shot below we can see a portion of the status bar. The current record indicator show that there are three records in the found set from a total of four records and that we are on record number two.



Unfortunately this information can be confusing. Users may not realise that the suppliers and customers are both subsets of the same data set. Especially as the search buttons may look and behave like navigation buttons, as they are in the image above. The application gives the impression that the different groups, such as customers and suppliers, are really different data sets. When faced with this users may think that the application has not shown them the full found set. If so, that undermines their trust in the application. If they try to correct this, by showing all records, they will end up with the wrong data set. That has a great potential to cause problems and will further undermine their trust in the application.
Many system designers have handled this situation by restricting user access to the status bar. This is a fairly radical move because the status bar contains standard elements of the user interface which are desirable and useful. And, in fact, as soon as the status bars is hidden from the user, the designer will have to provide all of those tools again. This takes a lot of effort, for designers and programmers. It would be nice to be able to make use of the status bar without confusing our users.
Better Alternatives
Data layers provide a simple way to provide the functionality that we want. It does this without needing duplicated data. It allows us to expose the status bar to the user safely. That frees us from having to reproduce those functions and gives the user standard, reliable functionality.
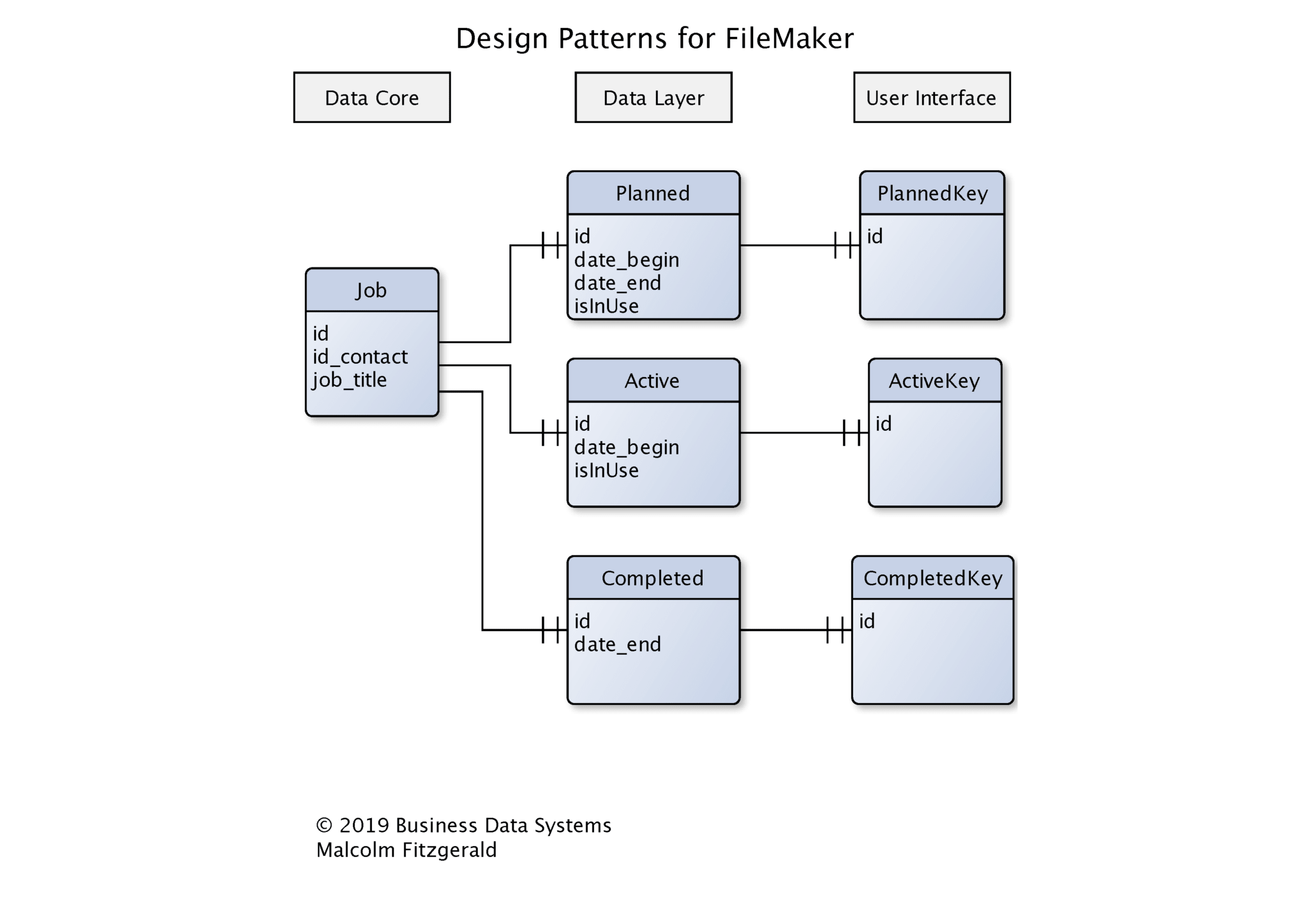
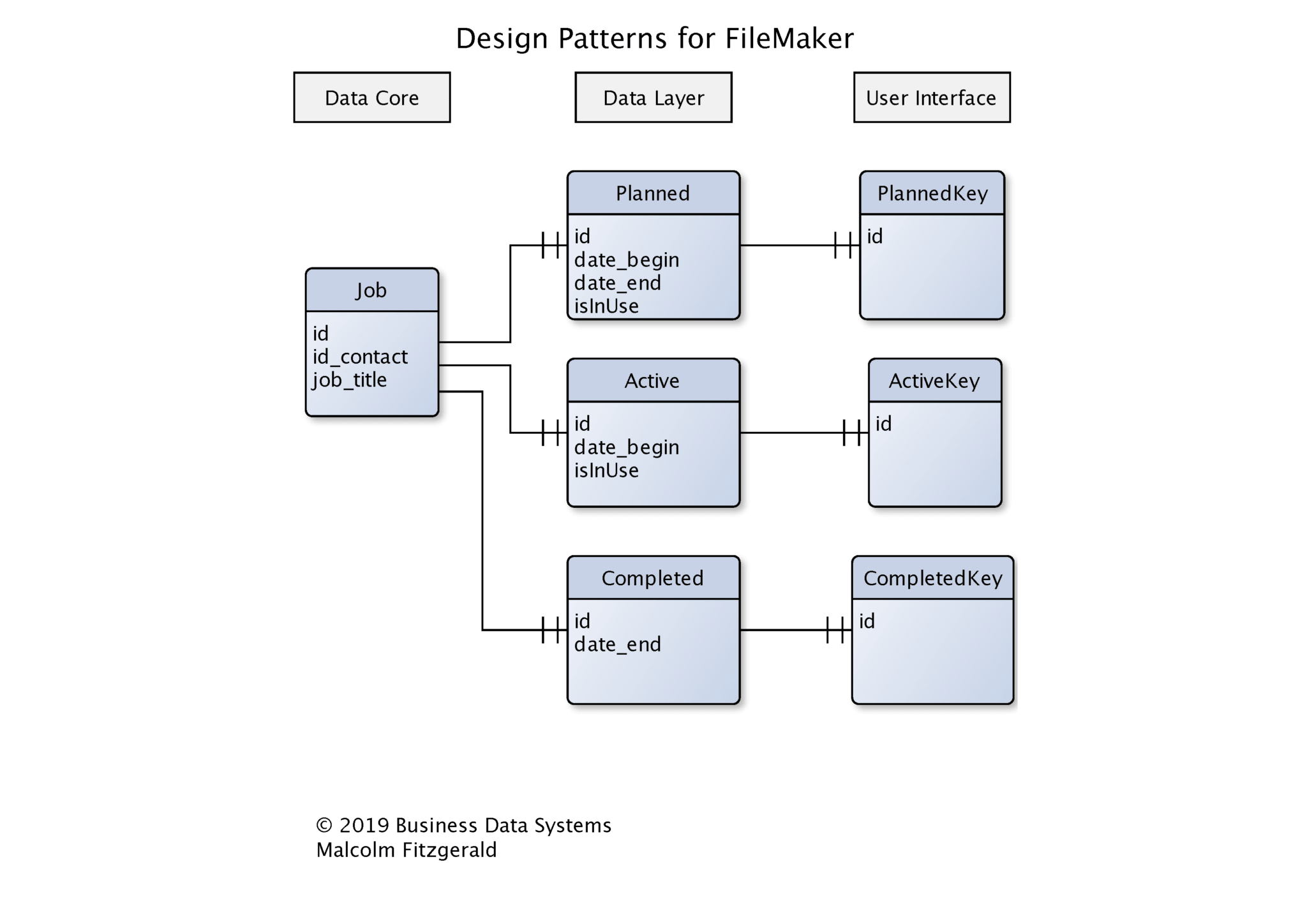
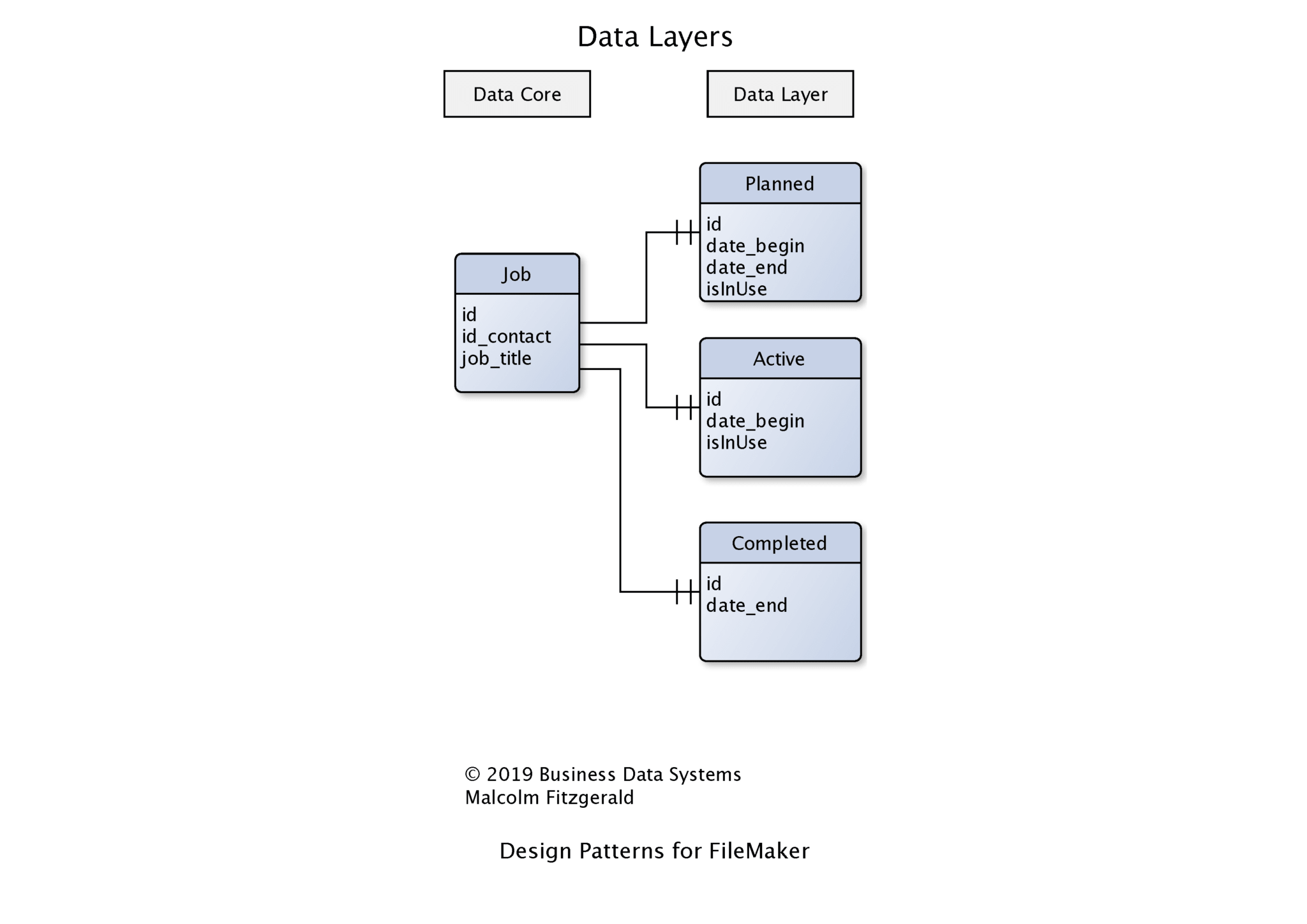
We will using a Job system to illustrate how that works. At the core of the system is a Jobs table which carries data for all jobs. That table stores all the jobs that have been discussed and planned ( such as quotes), all the jobs that are active and all the jobs that have been finished and invoiced. However, our business often wants to be able to handle these as if they were completely separate data sets. We do not want to have all our quotes mixed in with our invoices. How do we do that?
Data layers provide a way of sharing a core set of data, while generating different data sets that have unique properties. A data layer is a new data table and records have a one-to-one relationship with the core data. A data layer will link to the core data and have fields that store the data that is unique to it.


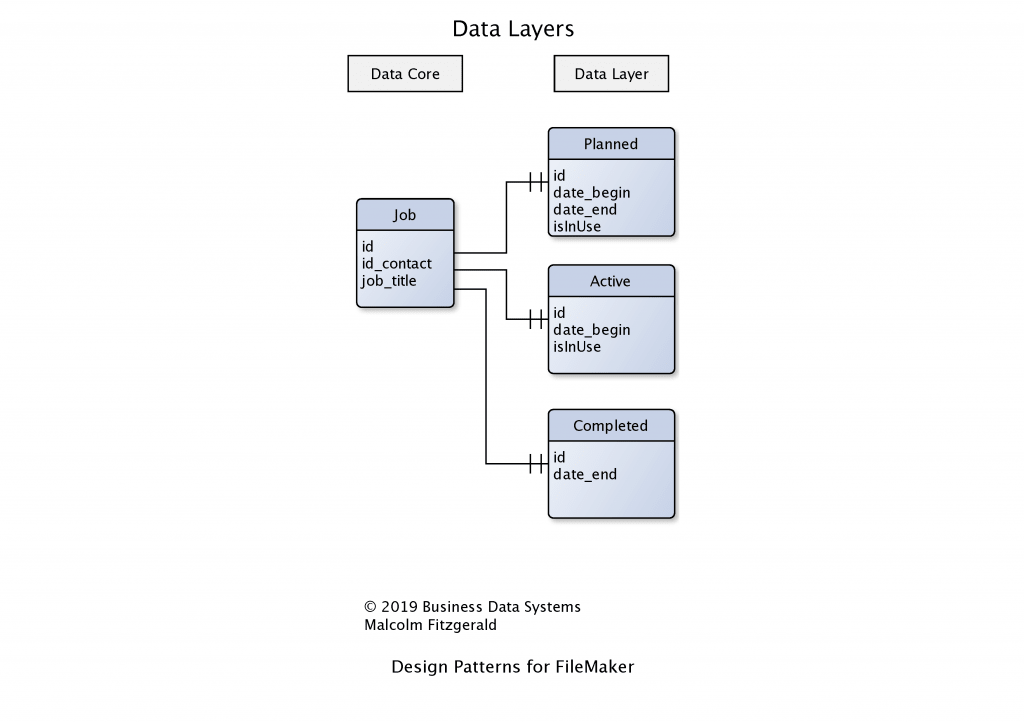
In this design pattern we link the data layer table with the data core table using the ID from the data core table. In other words, both the data core and the data layer share the same ID. In FileMaker this is achieved by the following steps:
- Set the ID field in the Data Core table to text and auto-generate an UUID
- Set the ID field in the Data Layer table to text. Do not generate an ID.
- Allow record creation on both sides of the relationship
We now use the data layer tables as the user interface .
Powerful Advantages
FileMaker has many powerful behaviours that we can take advantage of when we use this design pattern. They are especially useful if you are retro-fitting this design pattern to an existing system.
Low-data tables are the basis of complex structures
Applying Data Layers to Existing Solutions
The first thing to be aware of is that most existing layouts can be duplicated and re-purposed with very little effort. Re-purposing a core data table for use as a data layer table involves these steps
- Duplicate the layout
- Change the underlying Table Occurrence to the data layer table
- Change the layout name, text and field labels to reflect the new purpose
- In the core data table, find the correct set of records
- Import the IDs from the core data table into the ID field for the data layer
- repeat for each data layer
Depending on the specifics of your application this may be all you need to do. Some scripts may need to be tweaked but the data relations are all in place and work. You can now extend the behaviour of each layout to include the fields and functions which are specific to that data layer.
In the next article we’ll discuss Key Tables, which take advantage of under-the-hood performance features, and provide an even more compelling reason for using Data Layers.
{kind=link}
{kind=link}
{kind=link}
{kind=link}